
{kind=link}
最近又有一些认知被OpenAI教育了,这里跟大家分享一下。
太长不看版本
如果你希望有一个专属大模型
对于大模型能力的提升与边界的探索几乎是每一个从业人员的追求。
在过去,我们希望通过微调(SFT)的方式让大模型可以学习特定领域的知识,比如最近的新闻,最新的法律法规,Openai不知道的知识,比如我是谁。
我们也希望通过微调的方式,让大模型扮演特定的角色,处理特定的任务,比如扮演我们公司的认知智能大模型,扮演游戏中的某一个虚拟角色。

我们自己微调的一个钟离的大模型
似乎要完成以上两个目标,微调就是最优选择。
但是,最近看了OpenAI的报告,真的是被刷新认知了。
 OpenAI dev day
OpenAI dev day
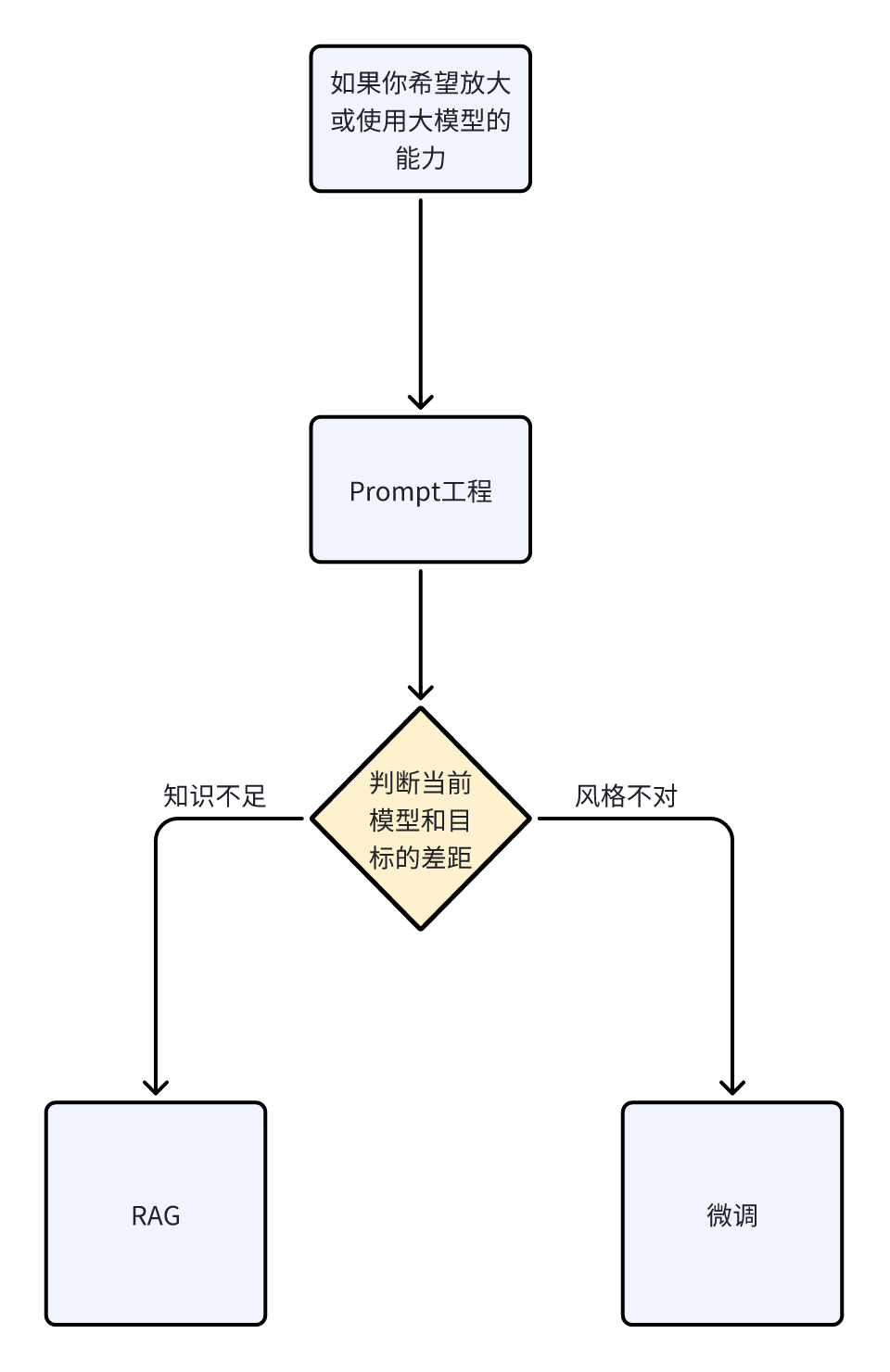
现在我们来介绍一下上面这张图,横轴表示,你希望大模型如何去表现,比如扮演什么样的一个角色。
纵轴表示,你希望大模型需要知道的东西。首先,在你做任何事情之前,Prompt 是你最优先要去尝试的。非常轻量级,可以快速验证你的MVP。
如果效果不够,你可以增加几轮对话,给大模型更多的指示。这个时候,你可以判断,你需要大模型了解更多知识,还是需要大模型按照特定风格表演。
通过RAG(检索增强生成),你可以让大模型快速学习特定知识。
通过微调模型,你可以让大模型扮演一个特定角色。
相比微调,RAG可能是大家完全忽视的一个点。
Prompt Engineering
首先介绍一下Prompt Engineering。

一定要从Prompt engineering 开始,它会给到你一个Baseline,通常我们以前在做机器学习的时候都会先用一个比较好实现的算法来先完成任务,然后再用特征工程,等等一些技巧,去提升算法的各种表现,这个时候你就会有一个直观的对比。
同样,也很可能,你的需求就靠Prompt就解决了,即使没有,你也会明白你的下一步应该如何操作,需要往哪个方向去提升。
如何写好Prompt真的是一门学问,这里OpenAI官方也贴心的给出的指导。

这里有一篇来自OpenAI的官方Prompt工程指南详解,建议深度反复阅读。这是大家最有可能最先反复跌倒的地方。
https://mp.weixin.qq.com/s/jOU2qT5o88tuZC1p6vLkJw
简单介绍一下最重要的就是
- 写出清晰的指令
- 提供参考文本
- 将复杂的任务拆分为更简单的子任务
- 给模型时间“思考”
- 使用外部工具
- 系统地测试变更
RAG检索增强生成
在你结束Prompt 工程时,你有两个选择。
如果你觉得模型的知识储备太贫乏了,你可以选择RAG。
如果你觉得模型没有你希望的特定的风格和格式,你可以选择微调。
RAG是一种结合了信息检索和文本生成的人工智能技术。
简单地说,我们可以将RAG比作一位研究员和作家的结合体。
想象一下,你问了一个复杂的问题,比如关于历史或科学的问题。一个研究员(信息检索部分)首先去图书馆(或者在这种情况下,是一个庞大的信息数据库)搜索相关的书籍和资料。他不会读整本书,而是找到与你的问题最相关的部分。
然后,这位研究员把找到的信息带给一位作家(文本生成部分)。这位作家非常擅长用清晰、连贯的方式表达思想。她看了研究员找到的资料,然后用自己的话重新表述这些信息,以回答你的问题。
在技术层面,RAG首先通过检索组件(类似研究员)在大量数据中搜索相关信息。然后,它利用一个生成模型(类似作家)来处理这些信息,并生成一个连贯、准确的回答。
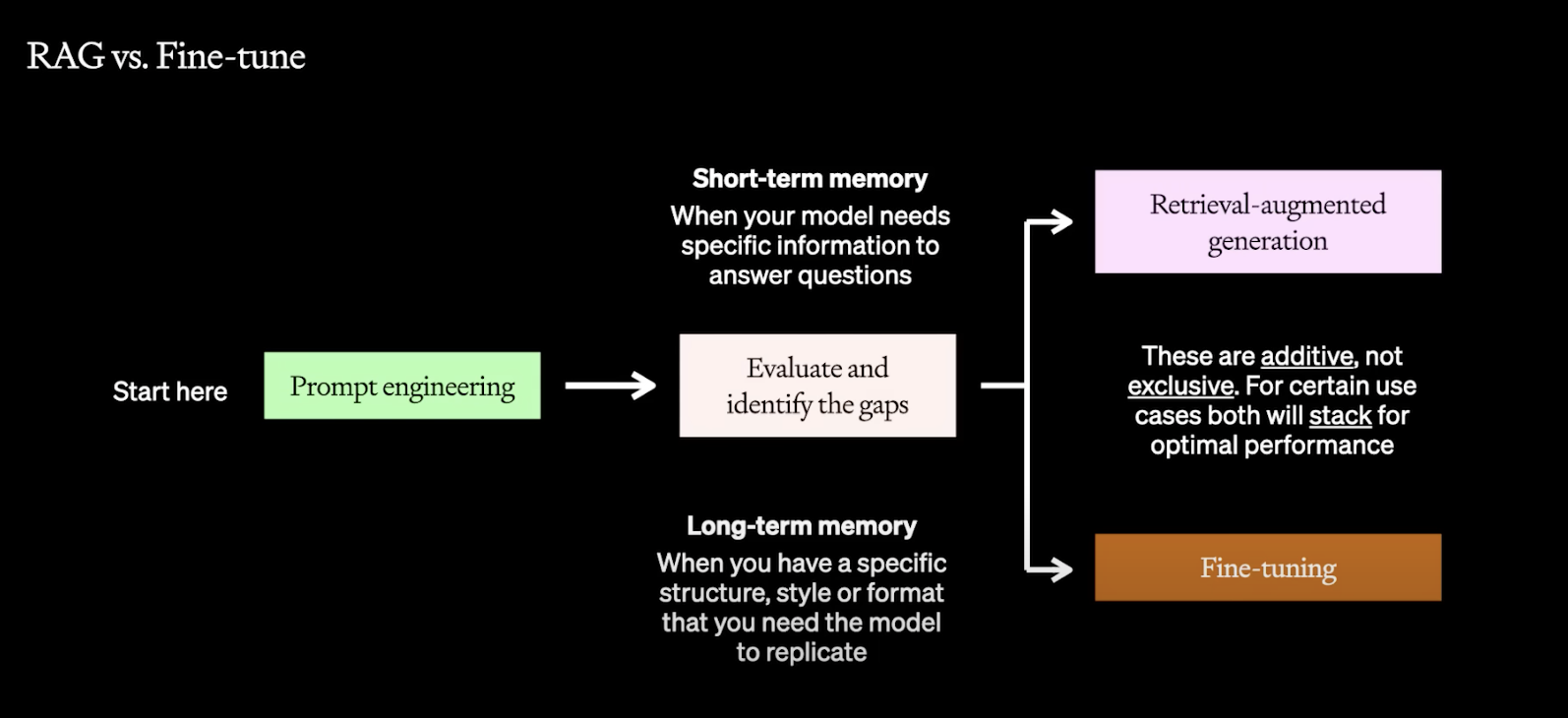
这里打个比方,Prompt工程比较像我告诉模型,你要去参加某个类型,某个学科的考试。
检索增强相当于把这门学科的书给大模型,你考试的时候可以翻书,可以检索。
微调则比较像让大模型深入学习这门课程的知识,让它把这些知识记在脑子里。

RAG非常适合用于解决大模型幻觉问题,同时也非常适合学习一些当前模型未掌握的知识。
但是RAG也有局限,它不能学习一整个学科,比如法律,医疗这些一整个学科。
也无法学习一整套语言风格和语言格式。
同样,他的tokens消耗是巨大的,因为每次检索都会消耗大量 tokens。
通常来说,我们可以通过RAG快速验证模型的 准确性是否达到目标水平。如果达到目标水平了,就可以通过微调,让他把整本书都记在脑子里。
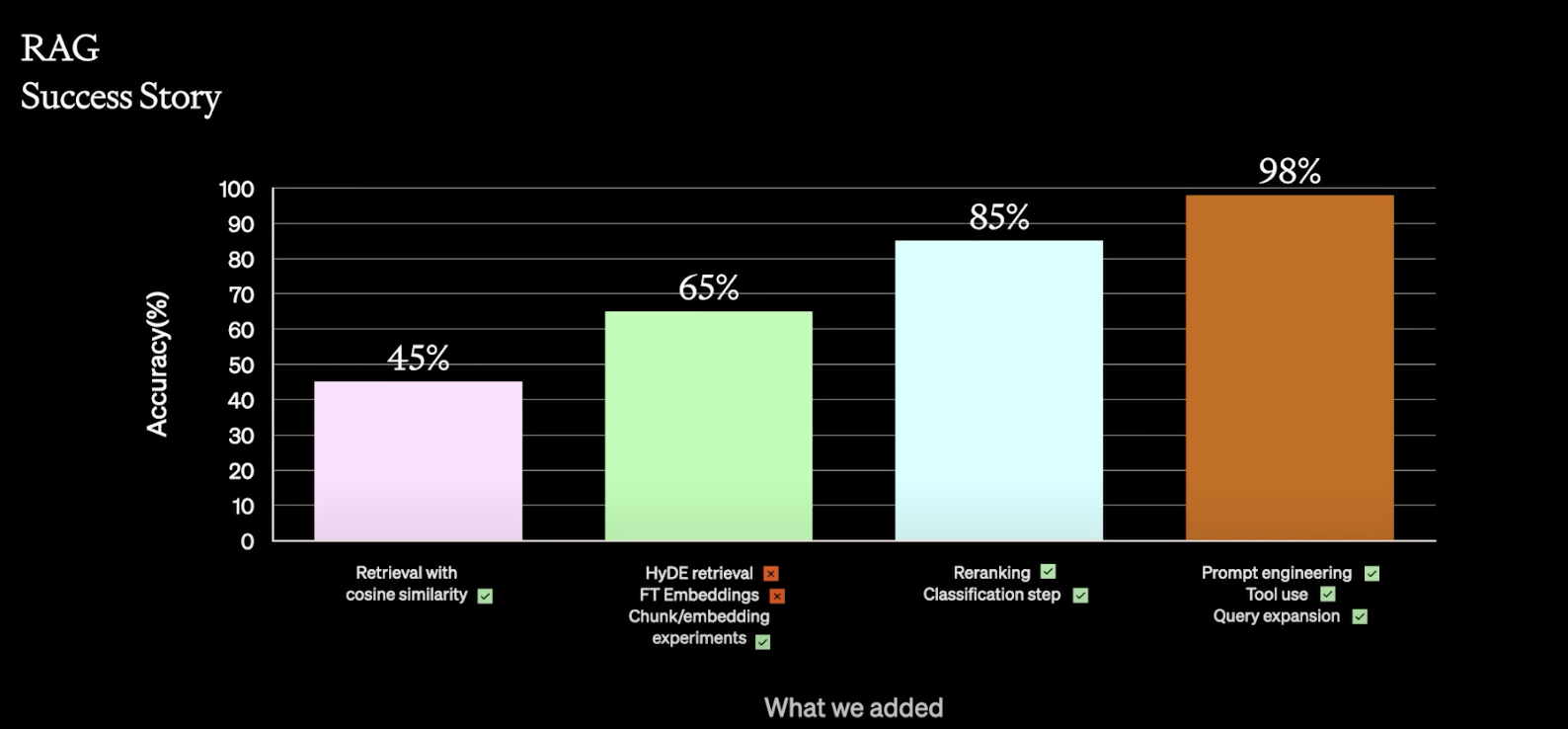
这里OpenAI展示了一个他们的成功试验,在使用RAG之前,他们通过几十次实验,取得了20%的准确率提升,后面用重排名,分类等操作,将模型准确率提高至85%,最后,通过特征工程,RAG,整个模型的准确率达到了98%。这炸裂的效果应该不用再过多介绍了吧。
同时,OpenAI分享了一个开源的,开箱即用的项目,Ragas,从四个维度评估RAG的质量。
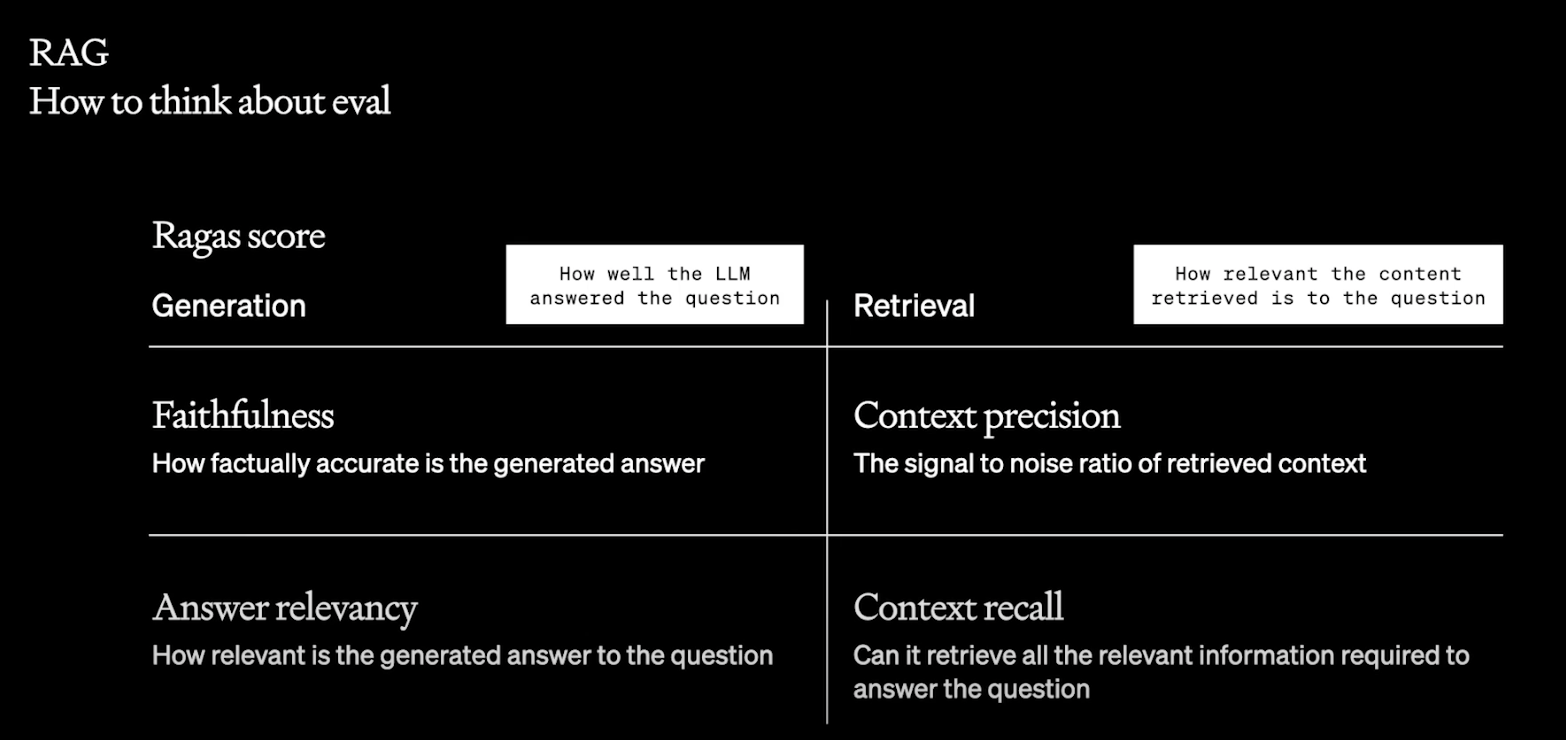
- Faithfulness (忠实度): 指生成的答案在事实上是否准确无误。
- Context Precision (上下文精确度): 指所使用的上下文信息是否精确和恰当。
- Answer Relevancy (答案相关性): 指生成的答案与所提问题的相关程度。
- Context Recall (上下文回忆): 指在生成答案时,能否全面地回忆并利用相关的上下文信息。
微调
微调的本质是让模型继续在一个小的,特定领域的数据集上训练,优化模型在特定任务上的表现。

微调的优势在于,你可以强调某一些已经存在于这个模型中的知识,定制它的回复风格,语气。
但是微调不擅长学习新的知识,不能快速迭代。
数据
这里想再强调一下数据的重要性。
一个差的数据集,可以让模型的表现大幅下降,是的,不是说用RAG,微调,模型的表现一定会提升。
如果你的数据集中含有大量的错误信息,模型也是会学习的,这都会给模型带来大量的幻觉。
而一个高质量的数据集的效果也是显而易见的。微软近期发布的Phi-2模型,一个仅仅只有27亿参数的模型,与市面上的130亿热门开源模型对比,表现出了优异的性能。
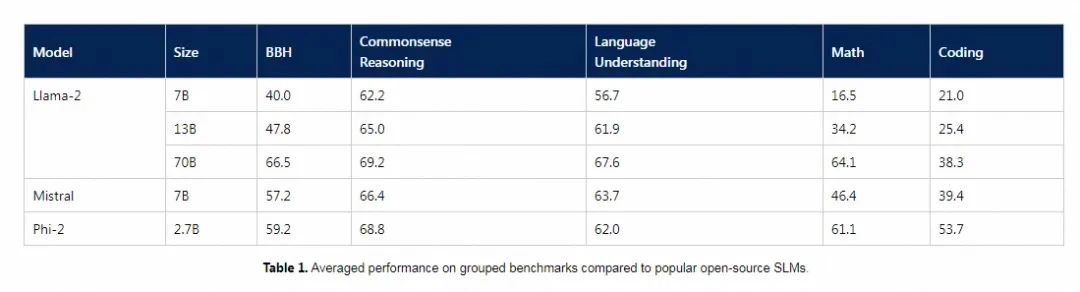
官方更是表示, Textbooks Are all you need!
Phi-2的训练数据混合了专门用于教授模型进行常识推理和掌握一般知识的合成数据集,包括科学、日常活动和心智理论等,并进一步筛选了具有教育价值和内容质量的网络数据来增强训练语料库。