几天前,谷歌发布了其最新最强的大语言模型Gemini 1.5版本,将能处理的上下文长度提高到100万toke
几天前,谷歌发布了其最新最强的大语言模型Gemini 1.5版本,将能处理的上下文长度提高到100万tokens(词元)。
这是一个相当亮眼的升级,可惜被Sora抢走了风头,但Gemini作为谷歌AI当前最重要的大语言模型,值得我们花点时间了解一下。
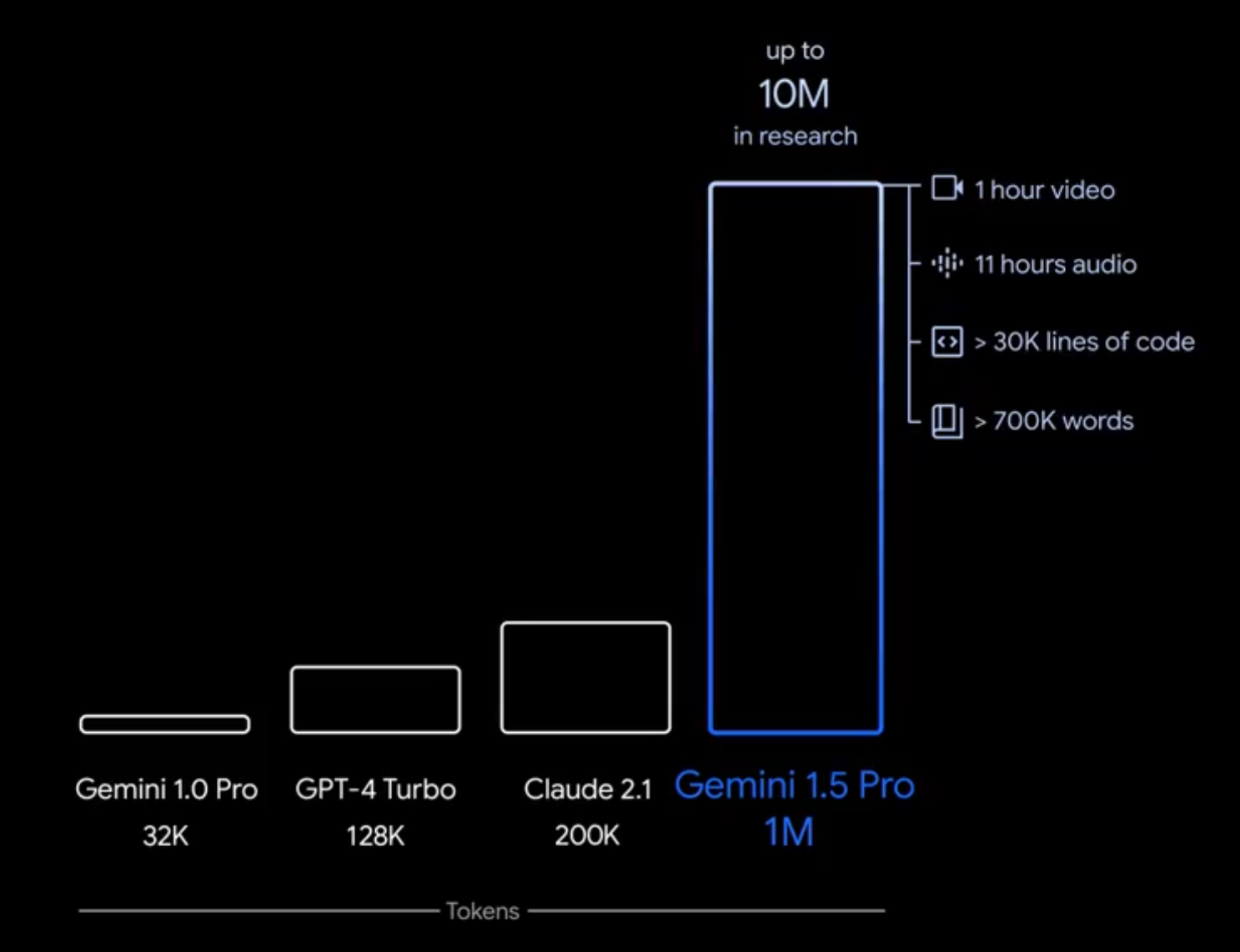
如上图所示,Gemini 1.5 Pro版支持的上下文长度是GPT-4 Turbo的近8倍,是Claude 2.1的5倍。
更形象地说,单次可以处理超过70万单词,或3万行代码,或11小时音频,或1小时视频。
更长的上下文带来了更大的技术挑战,和更多的资源消耗,因为模型的每次响应都要考虑最多100万tokens的内容。
补充一点,Gemini 1.5 Pro标准版配备的是128K的上下文,100万上下文仅对少数开发者和企业客户开放,而在内部研究中谷歌甚至测试了1000万上下文。
很明显,谷歌认为这很可能是大模型发展的一个重要方向。
Gemini可以理解、推理和识别阿波罗11号登月任务中的具体细节。
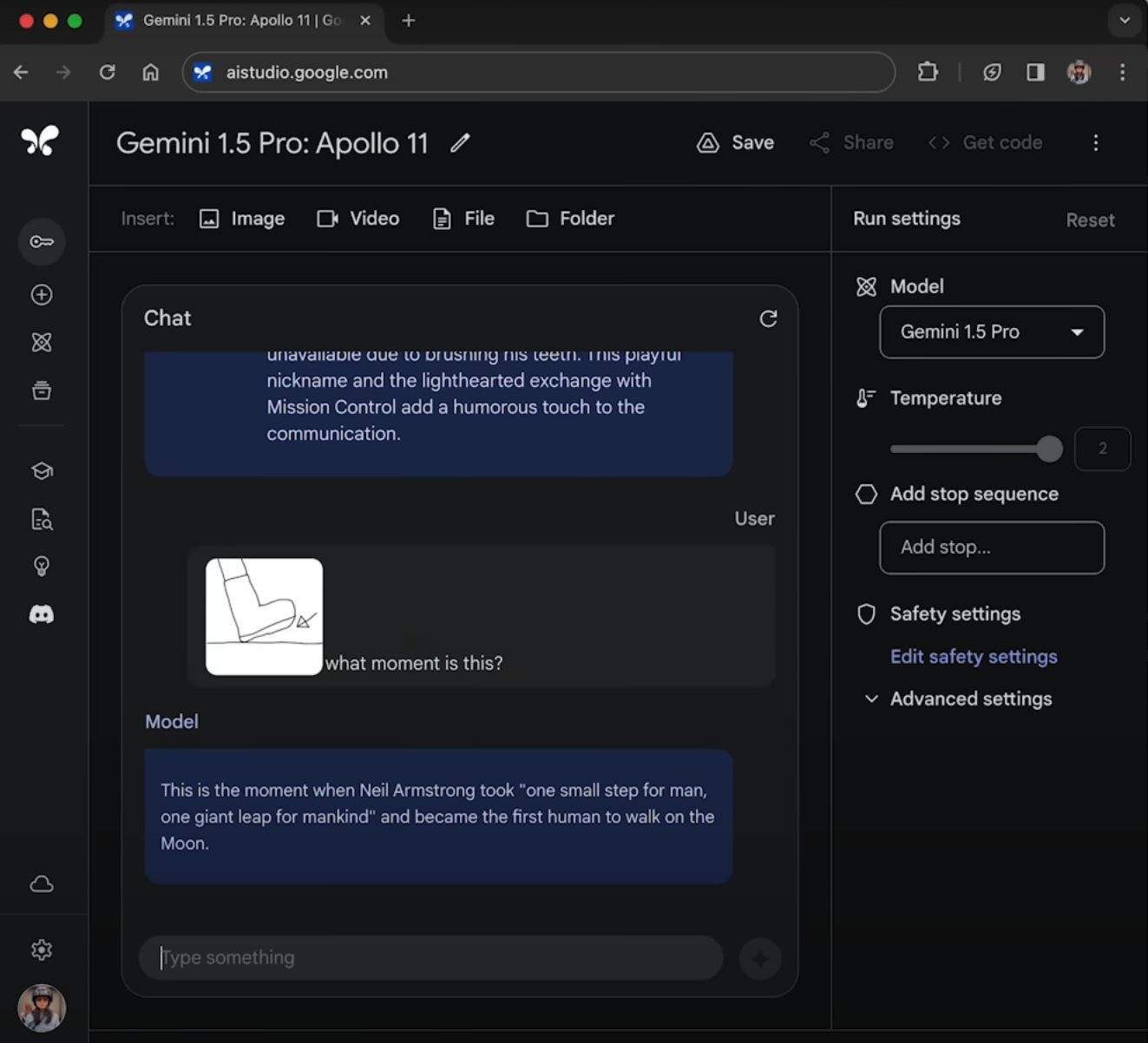
上传402页有关这次登月的记录(约32万tokens),然后提问:“这是什么时刻?”并附了一张简笔画。
Gemini可以非常准确地回答:这是阿姆斯特朗迈出“个人的一小步,人类的一大步”。(如下图)
请注意,在对话中并未对背景信息及简笔画内容进行解释,Gemini是完全基于提供的文档内容自行推理出来的。
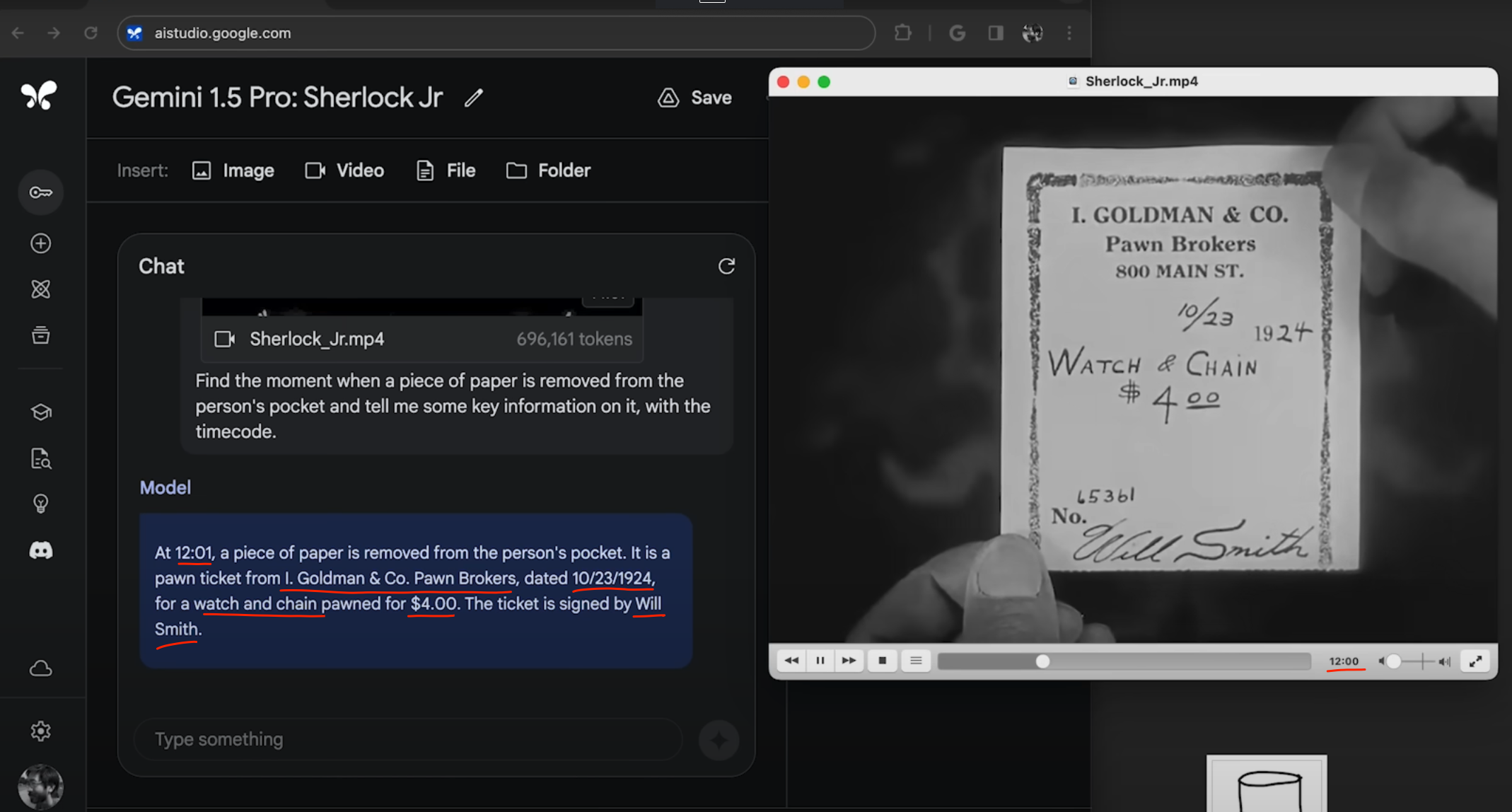
开发团队上传了一部44分钟的无声电影(约70万tokens),Gemini可以准确地分析电影中的具体情节,甚至包括一些小细节。
如下图,问:找到从某人口袋中掏出一张纸这个情节的具体时间,并说明纸上的关键信息,模型可以非常准确地找到具体画面并理解画面细节。
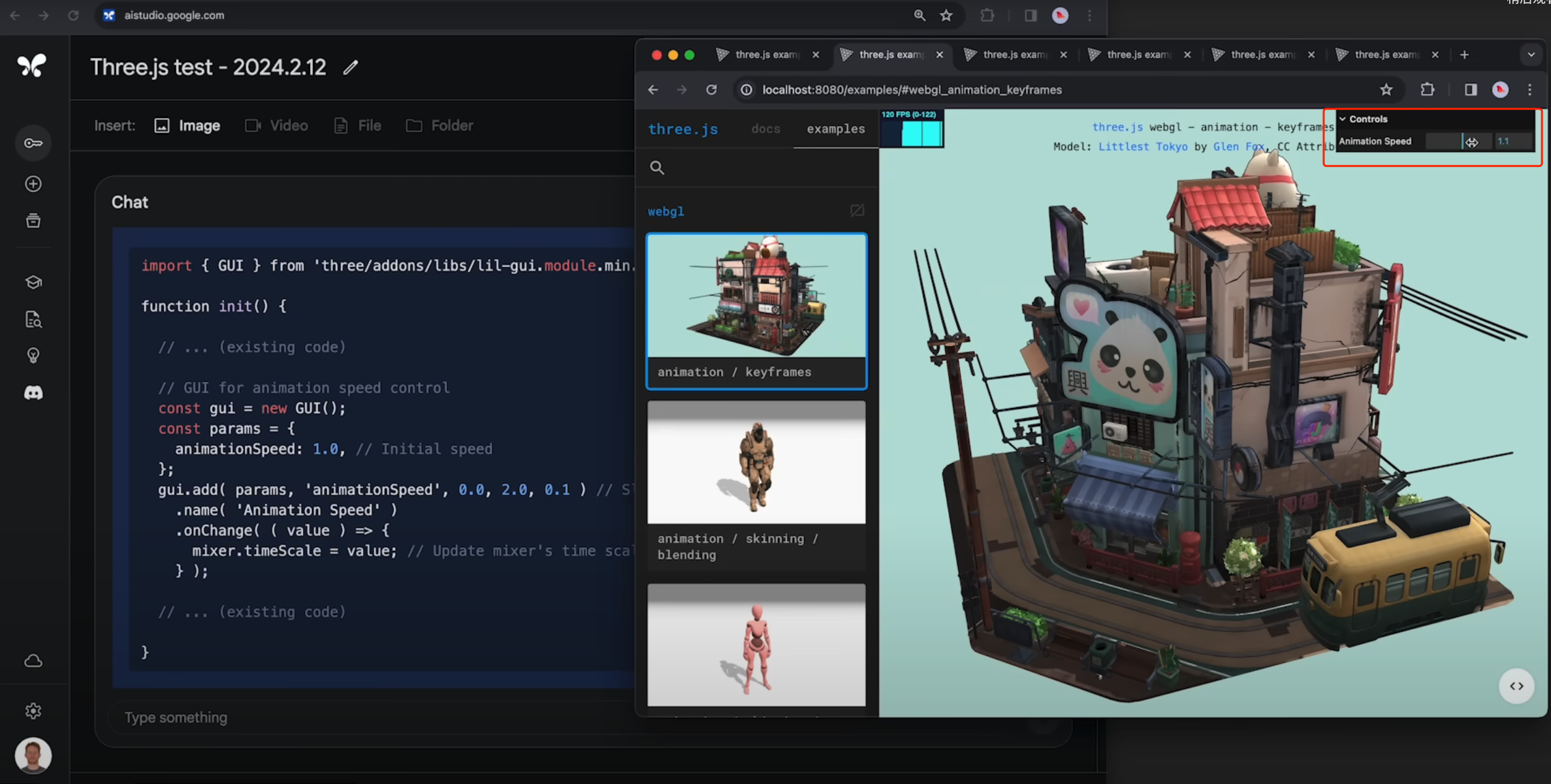
开发团队上传了包含几百个三维动画演示的js代码(约80万tokens),Gemini可以按照要求辅助开发工作。
让模型找到指定的动画,并对动画代码进行修改,以增加滑块来控制动画速度,模型最终实现的效果很不错(如下图)。
有了更长的上下文,就相当于有了更强大的解决问题的能力;
如果长下文长度很有限,模型将很难对具体问题进行推理,而只能给出较为笼统的答案。
对于大模型来说,越来越长的上下文带来越来越强的解答能力。
让我们拿电脑做个类比:大模型可以理解为是CPU,上下文窗口就是内存。
也许我们不必须无限扩容内存,更多时候可以搭配使用硬盘,从硬盘上检索信息。
用技术语言来说,这叫RAG(Retrieval Augmented Generation,检索增强生成),也是目前很重要的一个研究方向。
通过这篇文章,是否对Gemini 1.5的长上下文有了更多了解呢?欢迎转发分享你的看法。
参考资料:
https://deepmind.google/gemini
https://blog.google/technology/ai/google-gemini-next-generation-model-february-2024/

{kind=link}